Chapter 8 Univariate Statistics
8.1 Introduction
Statistical properties of a single parameter are invegated by means of univariate analysis. Such a parameter could, for example be the the size of population, the the gross domestic product (GDP) of the country in the world or life expactancy of the country. Because in most cases the data we collect depend on the sample size that are often limited because of either financial or logistic constraints. The method of univariate statistics assist us to draw from the sample conclusions that apply to the population as whole (Trauth 2015). R contains myriad of tools for statistical analysis. We will use the base package stats with other extended packages to illustrate concept of univariate statistics (R Core Team 2018).
8.2 Empical Distributions
Let us assume that we have collected a number of measurement of \(x_i\) from a specific area. The collection of data, or sample, as a subset of the population of interest can be writeen as a vector of \(x\) containing a total of \(N\) observations mathematically in equation (8.1). The vector \(x\) may contain a large number of data points and it may conseuently be difficult to understand its properties. Descriptive statists are therefore often used to summarize the characteristics of the data. THe statistical properties of the data set may be used to define an empirical distribution, which can then be compared to a theoretical one.
\[ \begin{equation} x = (x_1, x_2, \dots, x_n) \tag{8.1} \end{equation} \]
The most straightfoward way of investigating the sample characteristics is to plot the data graphically. Plotting all the data points along a single axis does nto reveal a great deal of information about the dat set. However, the density of the points along the scale does provide some information about the characteristics of the data. A widely used graphical display of continous univariate variable is the histogram7. Histogram provide vital information on the characteristics of the data like the central tendency, the dispersion and general shape of the distribution of quantitative data (Figure 8.1. In general term, the central tendency parameters—the mean and median define the center of the dataset, while the range and standard deviation provide information of how the data deviate from the center.
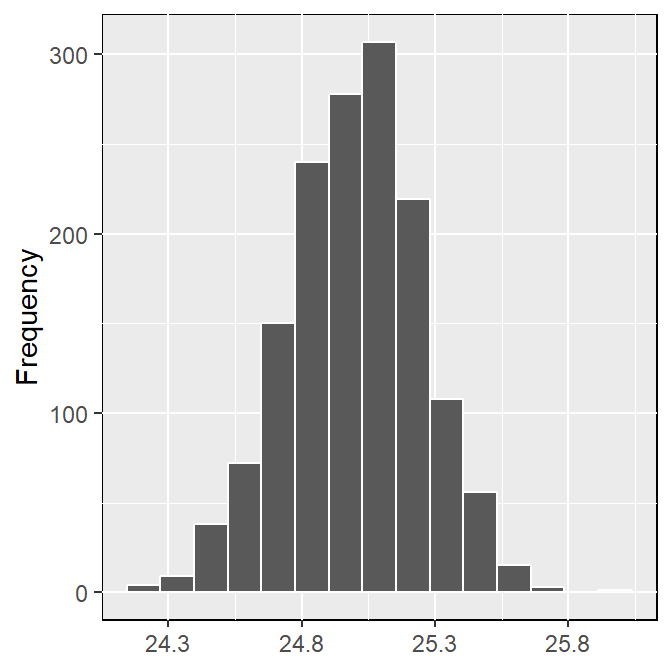
Figure 8.1: Emprical distribution of the frequency of quantitatively data
8.2.1 Measure of Central Tendency
The median and mean are parameters of central tendency or location represent the most important measure for describing emperical distribution of quantitative data. These parameters help locate the data on a linear scale. They represent a typical or best value that describe the data. The most most popular indicator of central tendency is the arithmetic mean, which is the sum of all data points divided by the total number of observations. The *arithmetic mean can be computed with equation (8.2)
\[ \begin{equation} \bar x = \frac{1}{N}\sum_{i=1}^N x_i \tag{8.2} \end{equation} \]
The arithmetic mean is also called mean or the average of a unvariate variable. The sample mean is used as an estimate of the population mean \(\mu\) for the underlying theoretical distribution. The arithmetric mean is, however, sensitive to outlier—extreme values that may be very dfferent from the majoriy of the data, hence median is often used an an alternative measured of central tendency. The median is the \(x\)-value that is in the middle of the variable, i.e 50% of the observations are smaller than the median and 50% are larger (Trauth 2015). The median of a quantitative data sorted in ascending order is mathematically written as equation (8.3) if \(N\) is odd; and equation (8.4) if \(N\) is even.
\[ \begin{equation} X = x_{(N+1)/2} \tag{8.3} \end{equation} \]
\[ \begin{equation} X =x_{N/2} + x_{(N+1)/2} \tag{8.4} \end{equation} \]
The third important measure for central tendeny is the mode. The mode is the most frequent \(x\)-value. Or for the grouped data, the the ccenter is the class with the largest number of observations. If the data values in the variable are unique that datase will have no mode. Frequency distribution with a single mode are called unimodla, but there variables with two modes(bimodal), three modes(trimodal) or four or more modes (multimodal) (Figure 8.2)
![Dispersion and shape of distribution, a-b) unimodal distribution showing a negative or positive skew, c-d) distribution showing a high or low kurtosis, e-f) bimodal and trimodal distribution showing two or more modes. Source [@trauth]](shape_distribution.png)
Figure 8.2: Dispersion and shape of distribution, a-b) unimodal distribution showing a negative or positive skew, c-d) distribution showing a high or low kurtosis, e-f) bimodal and trimodal distribution showing two or more modes. Source (Trauth 2015)
The mean, median, and mode are used when several quantities add together to produce a total, wherea the geometric mean is often used if these quantities are multiplied. Let us assume that the economy of country \(x\) increases by 10% the first year, 25% in the second year , and 60% in the last year. The average rate of increase is not the arithmetic mean, because the original number of individual has increase by a factor (not sum) of 1.1 after one year, 1.25 after the second year and r160/100 after the third year. The average growth of the economy is therefore calculated by the geometric mean with equation (8.5)
\[ \begin{equation} \bar x_g = (x_1 \times x_2 \times \dots x_n)^\frac{1}{N} \tag{8.5} \end{equation} \]
The average growth of these values is 1.3006 suggesting an approximate per annum growth in the economy of 30%. The arithmetic mean would result in an errenous value of 1.3167 of approximately 32% annual growth. The geometric mean is also a sueful mesure of central tendency for skewed or log-normal distributed data, in which the logarithms of the observation follow a Gausian or normal distribution. The geomeric mean, however, s not used for variables containing negative values.
The last is the harmonic mean used to derive a mean value for asymetric or log-normal distributed data similar to geometric mean. Unfortunate, the harmonic mean is sensitive to outlier. The harmonic mean is a better average when values are defined in relation to a particular unt. A commonly quoted example is averging velocity. The harmonic mean is also used to compute the mean of the sample sizes. The equation (8.6) is used to compute harmonic mean.
\[ \begin{equation} \bar x_H =\frac{N}{(\frac{1}{x_1} + \frac{1}{x_2} + \dots +\frac{1}{x_N})} \tag{8.6} \end{equation} \]
8.2.2 Measure of Dispersion
A second important component of the distribution is the dispersion. Some of the parameters that can be used to quantify dispersion are illustrated in figure 8.2. The simplest way to describe the dispersion of a dat ase is by the range— a difference between the highest and the lowest value in the quantitative data. The range can be computed with equation (8.7)
\[ \begin{equation} \delta x = X_{max} - X_{min} \tag{8.7} \end{equation} \]
Since the range is defined by the two extreme data points it is very susceptible to outliers and hence it is not a reliable measure of dispersion in most cases. Using the interquantile range of data—the middle 50% of the data attempt to overcome this problem. The widely used measure for dispersion is the standard deviation—the average deviation of each data point from the mean. The standard deviation of sample in an emprical distribution is often used as an estimate of the population standard deviation \(\sigma\) equation (8.8)
\[ \begin{equation} s = \sqrt {\frac{\sum \limits_{i=1}^N (x_i - \bar x)}{N-1}} \tag{8.8} \end{equation} \] The s formula for the poulation standard deviation uses \(N\) instead of \(N-1\) as the denominator. The sample standard deviation \(s\) is computed with \(N-1\) instead of \(N\) since it uses the sample mean instead of the unknown population mean. The sample mean, however, is computed from the data \(x_p\) which reduce the number of degrees of freedom by one. The degree of freedom are number of values in a distribution that are free to be varied. Dividing the average deviation of the data from the mean by \(N\) would therefore underestimate the population standard deviation \(\sigma\).
The variance is the third important measure of dispersion. The variance is the square of the standard deviation equation (8.9).
\[ \begin{equation} s^{2} = \frac{\sum\limits_{i=1}^{n} \left(x_{i} - \bar{x}\right)^{2}} {n-1} \tag{8.9} \end{equation} \]
Although the variance has the disadvantage of mismatch dimension with original data, it is extensively used in many applications than the standard deviation.
Other measure of distribution are skewness and kurtosis that are used to describe the shape of a frequency distribution (Fig). Skewness is a measure of the asymmetry of the tails of a distribution. A negative skew indicates the distribution is spread out more to the left of the mean value, assuming values increasing towards the right along the axis. Distribution with positive skewness have large tails that extend toward the right. Although Pearson’ formular for measure skewness is useful, the Fisher formular in equation (8.10) is used instead
\[ \begin{equation} skewness = \sum\limits_{i=1}^{n} {\frac{(x_i - \bar x)^3}{s^3}}\tag{8.10} \end{equation} \]
The second important measure of the shape of a distribution is the kurtosis that can be computed with a formulae in equation (8.11). Kurtosis measure whether the data are peaked or flat relative to a normal distribution. A high kurtosis indicates that the distribution has a distinct peak near the mean, whereas a low kurtosis shows a flat top near the mean and broad tails. Higher peakedness in a distribution results from rare extreme deviations, whereas low kurtosis is caused by frequent moderate deviations. A normal distribution has a kurtosis of three, and some definitions therefore substract three from the above term in order to set the kurtois of the normal distribution to zero.
\[ \begin{equation} kurtosis = \sum\limits_{i=1}^{n} {\frac{(x_i - \bar x)^4}{s^4}}\tag{8.11} \end{equation} \] .
References
Trauth, Martin. 2015. MATLAB® Recipes for Earth Sciences. Book. 4th ed. 2015. Berlin, Heidelberg: Berlin, Heidelberg : Springer Berlin Heidelberg : Imprint Springer.
R Core Team. 2018. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
A histogram is a barplot of a frequency distribution that is organized in intervals or classes↩